検索条件
タグで絞り込み
Macro(2)
Macro::macro 仕様(1)
Macro::macro 作成(1)
Tera Term::index(1)
Tera Term::導入編(3)
その他(2)
その他::技術情報(2)
全18件
(3/4ページ)
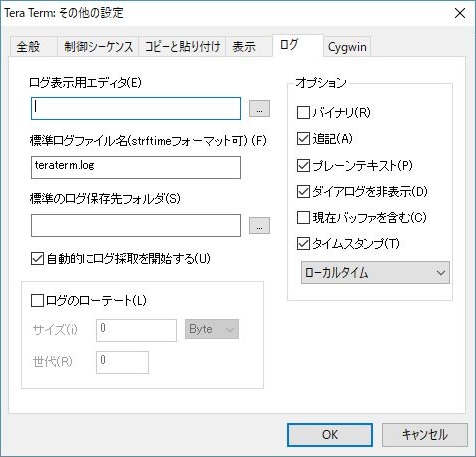
| オプション | チェック | 説明 |
|---|---|---|
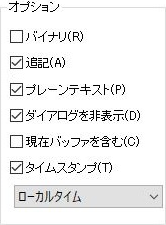
| バイナリ(R) |  | ホストから送られた文字をすべてファイルに書き込みます。エスケープシーケンス等を含みますので、テキストエディタで参照するには面倒ですが、あたかもホストから文字が送られてきたかのようにログの再生する機能を活用できます。 |
 | 漢字、改行コードは変換されて書き込まれます。エスケープシーケンスは書き込まれません。 | |
| 追記(A) | | 既存のファイルがあれば追記します。既存のものがなければ作ります。 |
| 既存のファイルがあれば上書きします。既存のものは消えます。既存のものがなければ作ります。 | |
| プレーンテキスト(P) | | ASCII 非表示文字を書き込まれなくなります。バイナリで取得している場合は無効になります。 |
| ASCII 非表示文字もログに書き込まれます。 | |
| ダイアログを非表示(D) | | ログダイアログが表示されなくなります。あとで表示させることは可能です。 |
| ログダイアログが表示されます。ログのファイル名や現在のサイズを確認したり、途中でログ取得を一時停止したりといったことがしたい場合に便利です。 | |
| 現在バッファを含む(C) | | 現在の Tera Term に表示されているバッファも含めてログファイルに書き出します。バッファ分は、タイムスタンプ出力を選択しても無効です |
| ログ取得開始時点からログファイルに書き出します。 | |
| タイムスタンプ(T) | | ログの行頭に時刻を追加できます。出力行の時刻は、その出力が開始された時刻です。コマンドが実行された時間を見る場合は、次の行のタイムスタンプになります。 |
| 表示されたとおりにログ出力されます。 |
| 選択肢 | 機能 |
|---|---|
| ローカルタイム | 端末の現在時刻を、ロケーションに応じて利用します。日本なら JST です。 |
| UTC | 端末の現在時刻を UTC に変換して利用します。 |
| 経過時間(Logging) | ログ取得開始時点からの経過時間を利用します。 |
| 経過時間(Connection) | 接続開始時点からの経過時間を利用します。 |
| 項目 | 設定内容 |
|---|---|
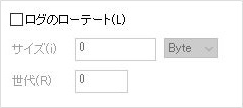
| サイズ(i) | ローテーションを発生させるログのサイズを設定します。 1文字がおよそ 1byte *1です。 |
| 世代(R) | 過去何世代まで保存するかを設定します。例えば5世代に設定した場合、6世代目となった過去ログは削除されます。 |
| 書式 | 意味 |
|---|---|
| &h | ホスト名。未接続の場合は空。 |
| &p | TCP ポート番号。未接続の場合は空。TCP 接続でないときも空。 |
| &u | ログオン中のユーザ名。 |
| %a | 曜日の省略形。 |
| %A | 曜日の正式名。 |
| %b | 月の省略形。 |
| %B | 月の正式名。 |
| %c | ロケールに対応する日付と時刻の表現。 |
| %d | 10 進数で表す月の日付 (01 ~ 31)。 |
| %H | 24 時間表記の時間 (00 ~ 23)。 |
| %I | 12 時間表記の時間 (01 ~ 12)。 |
| %j | 10 進数で表す年初からの日数 (001 ~ 366)。 |
| %m | 10 進数で表す月 (01 ~ 12)。 |
| %M | 10 進数で表す分 (00 ~ 59)。 |
| %p | 現在のロケールの午前/午後。 |
| %S | 10 進数で表す秒 (00 ~ 59)。 |
| %U | 10 進数で表す週の通し番号。日曜日を週の最初の日とする (00 ~ 53)。 |
| %w | 10 進数で表す曜日 (0 ~ 6、日曜日が 0)。 |
| %W | 10 進数で表す週の通し番号。月曜日を週の最初の日とする (00 ~ 53)。 |
| %x | 現在のロケールの日付表現。 |
| %X | 現在のロケールの時刻表現。 |
| %y | 10 進数で表す西暦の下 2 桁 (00 ~ 99)。 |
| %Y | 10 進数で表す 4 桁の西暦。 |
| %z, %Z | レジストリの設定に応じて、タイム ゾーンの名前または省略形を指定します。 タイム ゾーンが不明な場合は指定しません。 |
| %% | パーセント記号。 |
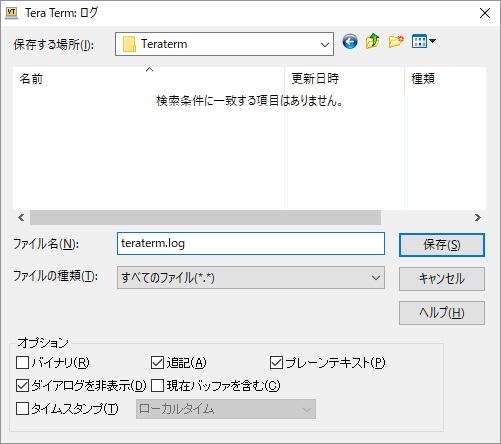
| オプション | チェック | 説明 |
|---|---|---|
| バイナリ(R) | | ホストから送られた文字をすべてファイルに書き込みます。 エスケープシーケンス等を含みますので、テキストエディタで参照するには面倒です。 ただし、Tera Term の機能である「ログを再生」ではバイナリでログを取得することで、後から、あたかもホストから文字が送られてきたかのようにログを再生する機能を活用できます。 |
| 漢字、改行コードは変換されて書き込まれます。 後からテキストエディタでログを参照するには適切です。 エスケープシーケンスは書き込まれません。 | |
| 追記(A) | | 既存のファイルがあれば追記します。 既存のものがなければ作ります。 |
| 既存のファイルがあれば上書きします。なので、既存だったものは内容が消えます。 既存のものがなければ作ります。 | |
| プレーンテキスト(P) | | ASCII 非表示文字が書き込まれなくなります。 バイナリにチェックを入れた場合は無効になります。 |
| ASCII 非表示文字もログに書き込まれます。 | |
| ダイアログを非表示(D) | | 旧来、ログを取得中には別に表示されていたログダイアログが表示されなくなります。 何十と Tera Term を開く場合には、倍の数のウィンドウが開かれてしまうので消せると便利です。 個別にログダイアログを表示させることは可能です。 |
| 旧来通り、ログ取得中にログダイアログが表示されます。 次のようなことをしたい場合は、表示させる方が便利です。 ・ログのファイル名や現在のサイズを確認する。 ・途中でログ取得を一時停止する。 | |
| 現在バッファを含む(C) | | 現在の Tera Term に表示されているバッファも含めてログファイルに書き出します。 バッファ分は、タイムスタンプ出力を選択しても無効です。 |
| ログ取得開始時点から Tera Term の画面に表示される情報をログファイルに書き出します。 テストエビデンスを取得したい場合などで有効と思います。 | |
| タイムスタンプ(T) | | ログの行頭に、時刻を追加できます。 デフォルトでは、ローカルタイムが出力されます。 出力行の時刻は、その出力が開始された時刻です。 コマンドが実行された時間を見る場合は、次の行のタイムスタンプになります。 バイナリにチェックを入れた場合は無効になります。 |
| 表示されたとおりにログ出力されます。 |
| 選択肢 | 機能 |
|---|---|
| ローカルタイム | 端末の現在時刻を、ロケーションに応じて利用します。日本なら JST です。 |
| UTC | 端末の現在時刻を UTC に変換して利用します。 |
| 経過時間(Logging) | ログ取得開始時点からの経過時間を利用します。 |
| 経過時間(Connection) | 接続開始時点からの経過時間を利用します。 |
| 書式 | 意味 |
|---|---|
| &h | ホスト名。未接続の場合は空。 |
| &p | TCP ポート番号。未接続の場合は空。TCP 接続でないときも空。 |
| &u | ログオン中のユーザ名。 |
| %a | 曜日の省略形。 |
| %A | 曜日の正式名。 |
| %b | 月の省略形。 |
| %B | 月の正式名。 |
| %c | ロケールに対応する日付と時刻の表現。 |
| %d | 10 進数で表す月の日付 (01 ~ 31)。 |
| %H | 24 時間表記の時間 (00 ~ 23)。 |
| %I | 12 時間表記の時間 (01 ~ 12)。 |
| %j | 10 進数で表す年初からの日数 (001 ~ 366)。 |
| %m | 10 進数で表す月 (01 ~ 12)。 |
| %M | 10 進数で表す分 (00 ~ 59)。 |
| %p | 現在のロケールの午前/午後。 |
| %S | 10 進数で表す秒 (00 ~ 59)。 |
| %U | 10 進数で表す週の通し番号。日曜日を週の最初の日とする (00 ~ 53)。 |
| %w | 10 進数で表す曜日 (0 ~ 6、日曜日が 0)。 |
| %W | 10 進数で表す週の通し番号。月曜日を週の最初の日とする (00 ~ 53)。 |
| %x | 現在のロケールの日付表現。 |
| %X | 現在のロケールの時刻表現。 |
| %y | 10 進数で表す西暦の下 2 桁 (00 ~ 99)。 |
| %Y | 10 進数で表す 4 桁の西暦。 |
| %z, %Z | レジストリの設定に応じて、タイム ゾーンの名前または省略形を指定します。 タイム ゾーンが不明な場合は指定しません。 |
| %% | パーセント記号。 |
| コマンド | バージョン | 機能の簡易説明 | |
|---|---|---|---|
| 通 信 | logautoclosemode | 4.79以降 | マクロ終了時、自動的にログ採取を停止する。 |
| 【Usage】logautoclosemode <flag> | |||
| logclose | Tera Term のログを終了する。 | ||
| 【Usage】logclose | |||
| loginfo | 4.73以降 | Tera Term のログ取得状態を得る | |
| 【Usage】loginfo <strvar> | |||
| logopen | Tera Term のログを開始する。 | ||
| 【Usage】logopen <file name> <binary flag> <append flag> | |||
| 4.61以降 | ログ再生可能なバイナリオプションの追加。 | ||
| 【Usage】長いため別記 *1 | |||
| 4.62以降 | ログを開けたかどうか result を返す仕様の追加。 | ||
| 4.80以降 | 端末バッファをログへ含めるオプションの追加。 | ||
| 【Usage】長いため別記 *2 | |||
| 4.97以降 | ログ行頭へタイムスタンプを追記するオプションの追加。 | ||
| 【Usage】長いため別記 *3 | |||
| logpause | Tera Term のログを一時中断する。 | ||
| 【Usage】logpause | |||
| logrotate | 4.78以降 | ログをローテートする。 | |
| 【Usage 1】logrotate 'size' '<size>' 【Usage 2】logrotate 'rotate' <count> 【Usage 3】logrotate 'halt' | |||
| logstart | 中断していた Tera Term のログを再開する。 | ||
| 【Usage】logstart | |||
| logwrite | 文字列をログに書き込む。 | ||
| 【Usage】logwrite <string> | |||
$ echo 'hello world!' hello world!
:%s/\r//gと入力することで、ファイル内のすべての \r (CR) が削除 (正確には \r を '' (Null) に置換) されます。