2019/07/18(木)filereadln のシェル連携文字コード変換
2021/05/21 06:45
- filereadln のシェル連携文字コード変換
- 検証環境
- 検証コード
- その他・備考
filereadln のシェル連携文字コード変換
Tera Term バージョン 4.102 から、マクロファイルのエンコーディングとして UTF-8 および UTF-16 (いずれも BOM の有無はチェック) に対応しているものの、filereadln はどちらにも未対応のため、対象ファイルが UTF-8 または UTF-16 の場合に文字化けします。これは、Tera Term マクロファイルの文字コードに関係なく、filereadln で読み込むファイルが UTF の日本語表記である場合*1に必ず起こります。
気づいたきっかけは、strsplit を利用して CSV ファイルの内容を strdim と listbox で定義されたファイルに変換した後 include で読み込ませられれば、文字列型配列を生成する作業が格段に楽になると思ったことでした。
このとき、Tera Term マクロファイルを UTF-8 (BOM付) で作成していたので、何となく CSV も日本語が扱えるだろうと思い込んでしまったのが悪かったですね。
ということで、ユーザとして対策を考えてみました。
- UTF-8 ではなく SJIS を利用する
- iconv を利用する
- Teraterm プロジェクトにバグ報告する
でも、できれば扱うファイルの文字コードは統一したかったなぁ……。
Teraterm プロジェクトに連絡するのは、OSDN のアカウントが必要そう。
んー、アカウントを作る必要があるんだよね?
でもこれ、バグなのか?
もともと SJIS を利用する前提だったのだから、仕様じゃないのか?
びっみょー。
という消去法で UTF-8 の CSV を使う以上は、外部の文字コード変換を利用するのが手っ取り早そうでした。
その、外部の文字コード変換を利用する方法として、ログイン先シェル環境にある iconv を利用しようというネタです。
利用できるのが UNIX / Linux へログインしている場合に限られるので、自分の利用目的としてはちょっと微妙のためメモ扱いで公開します。
検証環境
Tera Term
Tera Term バージョン 4.103Linux
Rasbian *2 VERSION="9 (stretch)"検証コード
UTF-8 でも日本語表記が OK な例
マクロファイル内部で定義している場合strings = '日本語,english,分割,split' strsplit strings ',' messagebox groupmatchstr1 "groupmatchstr1"
読み込む CSV が UTF-8 の日本語表記で文字化けする例
CSV ファイル (UTF-8(BOM無))と、そのファイルを読み込むマクロファイルの2つが必要です。sample.csv (UTF-8 BOM無)
・sample.csv の中身(UTF-8 BOM無*3)日本語,english,分割,split
filereadln で NG な例
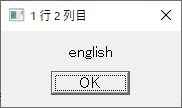
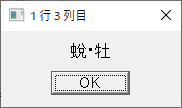
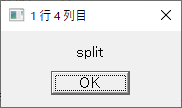
・sample.csv を読んで分割するマクロ; 対象ファイルを定義 targetCSVFile = 'sample.csv' ; ファイルを開く fileopen fh targetCSVFile 0 ; 1行目を読む filereadln fh fhline ; 1行目を表示する messagebox fhline '1 行目 全体' ; 1列目を表示する strsplit fhline ',' messagebox groupmatchstr1 "1 行 1 列目" messagebox groupmatchstr2 "1 行 2 列目" messagebox groupmatchstr3 "1 行 3 列目" messagebox groupmatchstr4 "1 行 4 列目" fileclose fh
実行結果
1行目全体の表示
1行目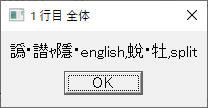
1行目各列の表示
1列目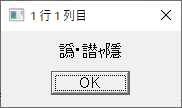
2列目
3列目
4列目
読み込む CSV が SJIS の日本語表記で文字化けしない例
CSV ファイル (SJIS)と、そのファイルを読み込むマクロファイルの2つが必要です。sample.csv (SJIS)
・sample.csv の中身(SJIS)日本語,english,分割,splitNG だった場合のものを SJIS に変換して再利用しています。
filereadln で OK な例
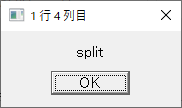
・sample.csv を読んで分割するマクロNG だった場合と同じものを再利用しています。
実行結果
1行目全体の表示
1行目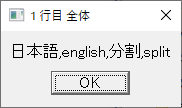
1行目各列の表示
1列目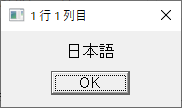
2列目
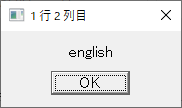
3列目
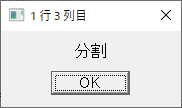
4列目
読み込む CSV が UTF-8 の日本語表記なので文字化けを iconv で何とかする例(中途半端)
CSV ファイル (UTF-8(BOM無))と、そのファイルを読み込むマクロファイルの2つが必要です。sample.csv (UTF-8 BOM無)
・sample.csv の中身(UTF-8 BOM無*3)日本語,english,分割,split
filereadln で NG な例
・sample.csv を読んで分割するマクロ; 対象ファイルを定義 targetCSVFile = 'sample.csv' ; ファイルを開く fileopen fh targetCSVFile 0 ; 1行目を読む filereadln fh fhline ; 1行目を表示する messagebox fhline '1 行目 全体' ; 1列目を表示する targetstr = groupmatchstr1 call subiconv ; 2列目を表示する ;targetstr = groupmatchstr2 ;call subiconv ; ; 3列目を表示する ;targetstr = groupmatchstr3 ;call subiconv ; ; 4列目を表示する ;targetstr = groupmatchstr4 ;call subiconv fileclose fh end :subiconv ;;; 文字列をシェル(iconv)で変換するサブルーチン ;;; ; シェルへ送る文字列の生成 sprintf2 cnvstr "echo "#34"%s"#34" | iconv -f UTF-8 -t CP932" targetstr ; 送信後、受けとる文字数のカウント strlen targetstr strlength = result ; 文字列を送信 sendln cnvstr ; 余分なバッファを捨てる(仮) waitln '' ; 変換した後の文字列を待つ waitn strlength ; 受け取った内容をメッセージボックスへ出力 messagebox inputstr 'inputstr' returnさて、これで変換できるかな?
と思ったものの、サンプルにした "日本語" の "語" の部分が文字化け。
記事用に作ったサンプルでは文字化けしてしまったものの、環境を示す "本番" や "開発" といった文字では問題なく変換できていたコードなので、推測ながら文字コードで何かがコンフリクトしているように思える。
また、余分なバッファを捨てる部分も、他に適切なコマンドがあった気がしないでもない。
(動作確認用にワークアラウンド的なコーディングをしているので、ここは気にしないことにする)
以後の宿題として、2019/7/18 の作業としてはここまで。